私は2016年から既存の機械学習系超解像プログラムを試したり、改造したり、自分で新規なネットワークと学習スクリプトを作成したりして来ました。
ネットワークの活性化関数としては2018年12月からSwish活性化関数を利用しておりました。
Swish(x) = x * Sigmoid(x) = x / (1 + exp(-x))
活性化関数として有名なのはReLUですが、あれは入力0以下は出力が0なので傾きが無く、負の領域は学習不能でデッド ニューロン化してしまいます。
また、出力ランドスケープも滑らかではありません。
対してSwishは連続な関数で全領域で無限回微分可能であり、ReLU同様に出力に上限は無く、下限はあるので正則化が働き、(0, 0)を通り、負の極大より負の向きでは出力が0に漸近し、出力ランドスケープも滑らかであり、非単調性なので表現力もあります。
このSwishを更に高品質化した活性化関数が一時期話題になったMishです。
Mish(x) = s * tanh(ln(1 + exp(x)))
全般的にMish活性化関数はSwishよりも少しだけ性能が良いようですが、残念な点があります。
それは計算の遅さです。
特に誤差逆伝播の為の微分が複雑でexponential計算が多くて重いです。
私も試してみましたが、遅過ぎて性能向上のメリットを帳消しにしてしまいました。
そして本命、TanhExp活性化関数の登場です。
arxivのTanhExp論文掲載ページ: https://arxiv.org/abs/2003.09855
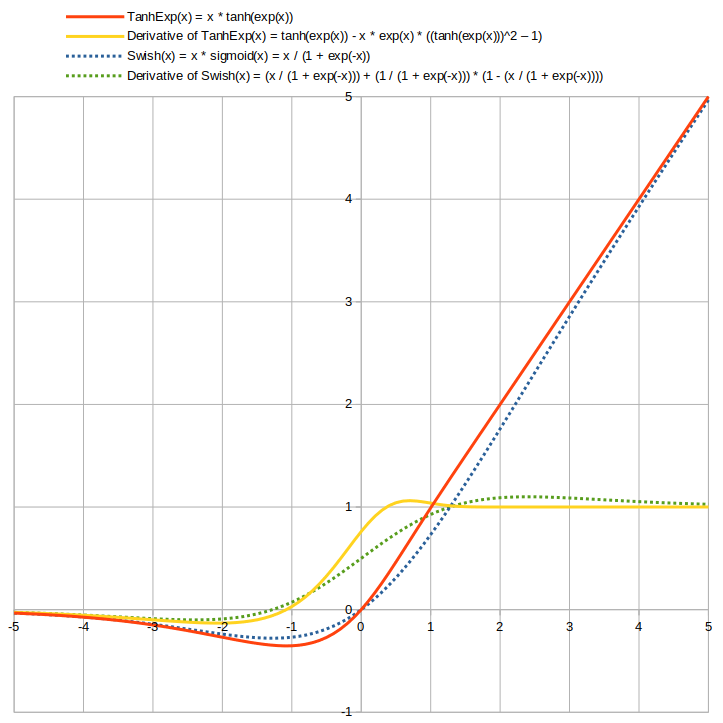
TanhExp(x) = x * tanh(exp(x))
シンプルな式です。
微分も、
dy/dx = tanh(exp(x)) – x * exp(x) * ((tanh(exp(x)))^2 – 1)
と割とシンプルです。
しかもSwishなどよりも入力0から1付近での傾きが大きいので誤差が逆伝播し易く、微分値が1を超えた後は直ぐに1に近付くのでTanhExpを重ねても値が爆発し難いという性質があります。
論文によると、全般的にReLUやSwishやMishをも上回る性能だそうです。
以下にTanhExp活性化関数とSwish活性化関数を比較したグラフを掲載致します。
(グラフの作成にはLibreOfficeを使用致しました)
実際にPyTorchにて自作して試してみたところ、Swishとほぼ変わらない計算速度でした。
最初、NaNを出してしまったので考えてみたら、exponentialなので少しの過大入力でexp()がinfになってしまうのが原因のようでした。
そこで torch.where(condition, x, y) を利用して出力を制御したところ、NaNは出なくなりました。
因みに学習率はSwishよりも更に小さい方が安定するようです。

このスクリーンショット画像は、Residual of ResidualでCNNな小さ目の超解像復元ネットワークで活性化関数を変えて同じ回数のiterationで比較したものです。
左はTanhExp活性化関数で、右はSwish活性化関数です。
処理に要した時間はほぼ同じで、偶然かもしれませんが、TanhExpの方が色が濃く、コントラストがあり、少しはっきりしているように見えます。
この結果を受けまして、私は今後はTanhExp活性化関数を使用して行きたいと思います。
ところで、Webに様々な活性化関数の一覧を掲載して下さっているページがございましたので、勝手ながら紹介させて頂きたいと思います。
“活性化関数一覧 (2020)” Qiita: https://qiita.com/kuroitu/items/73cd401afd463a78115a
多様な活性化関数とその導関数、各々のグラフまで掲載してあり、とても分り易く素晴らしい記事です。
PyTorchのTanhExp活性化関数のコード スニペットを掲載しますので、御自由にお使い下さい。
注意: 間違いがあっても私は責任を負えませんので、自己責任にてお願い致します。
# TanhExp activation function.
class TanhExpFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
result = torch.where(x > 20, x, x * torch.tanh(torch.exp(x)))
ctx.save_for_backward(x)
return result
@staticmethod
def backward(ctx, grad_output):
# GPUが利用可能ならGPUを利用する。
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
x = ctx.saved_tensors[0]
one = torch.tensor([1.0], device=torch.device(device))
x = torch.where(x > 20, one, torch.tanh(torch.exp(x)) - x * torch.exp(x) * (torch.square(torch.tanh(torch.exp(x))) - 1.0))
return grad_output * x
class TanhExp(torch.nn.Module):
def forward(self, x):
return TanhExpFunction.apply(x)

コメント