2023年3月現在、私は機械学習フレームワークのPyTorch 2.0で深層畳み込みニューラル ネットワーク(Deep Convolutional Neural Network / DCNN)による画像復元超解像(Image Restoration and Super-Resolution)モデルの機械学習(Machine Learning / ML)を試して遊んでおります。
この度、“NVIDIA GeForce RTX 3060” GPUと12GBのGDDR6 VRAMを搭載した “MSI GeForce RTX 3060 VENTUS 2X 12G OC” というグラフィクス カードを購入、自作PCに搭載し、CUDAにて機械学習処理を実行する事にいたしました。
ブログ記事: NVIDIA GeForce RTX 3060 GPU搭載グラフィクス カードを導入し、電力制限を設定した。
しかしながら、2023年3月現在で私が試しているDCNNモデルは、学習可能なパラメーター数が364,931,587、約3.65億ほど有り、VRAMが32GBくらいないと誤差逆伝播の為に保存される順伝播の計算の途中のデータがVRAMに乗せ切れず、OoM(Out of Memory)してしまいます。
そこで、順伝播の中間計算データはCPU側のメインメモリーに保存し、必要な分だけGPU側に戻す事で少ないVRAMでも処理出来るようにする “CPU Offloading” という仕組みを利用する事にいたしました。
CPU Offloadingにも色々なやり方が有りますが、PyTorch 2.0では標準で入っている機能だけでこれが可能です。
以下にCPU offloadingするのに必要だったコードを載せます。
無関係な部分は省略(omitted)しています。
import os
------------------------------------------
(omitted)
------------------------------------------
import torch
from torch.distributed.fsdp import FullyShardedDataParallel
from torch.distributed.fsdp.fully_sharded_data_parallel import CPUOffload
------------------------------------------
(omitted)
------------------------------------------
# TanhExp activation function.
class TanhExpFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
with torch.autograd.graph.save_on_cpu(pin_memory=True):
result = torch.where(x > 20, x, x * torch.tanh(torch.exp(x)))
ctx.save_for_backward(x)
return result
@staticmethod
def backward(ctx, grad_output):
# GPUが利用可能ならGPUを利用する。
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
x = ctx.saved_tensors[0]
one = torch.tensor([1.0], device=torch.device(device))
x = torch.where(x > 20, one, torch.tanh(torch.exp(x)) - x * torch.exp(x) * (torch.square(torch.tanh(torch.exp(x))) - 1.0))
return grad_output * x
class TanhExp(torch.nn.Module):
def forward(self, x):
return TanhExpFunction.apply(x)
------------------------------------------
(omitted)
------------------------------------------
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
------------------------------------------
(omitted)
------------------------------------------
self.layers = torch.nn.ModuleList(layersList)
def forward(self, x):
with torch.autograd.graph.save_on_cpu(pin_memory=True):
i = 0
x = self.layers[i](x) # PixelShuffle
i += 1
x = self.layers[i](x) # Conv2d
i += 1
x = self.layers[i](x) # GroupNorm
i += 1
x = self.layers[i](x) # TanhExp
i += 1
# Residual Blocks
x1 = x
for k in range(self.nResidualBlocks2):
x0 = x
for j in range(self.nResidualBlocks1):
h = self.layers[i](x) # Conv2d
i += 1
h = self.layers[i](h) # TanhExp
------------------------------------------
(omitted)
------------------------------------------
x = self.layers[i](x) # Sigmoid
return x
class LossFunction(torch.nn.Module):
def __init__(self):
super(LossFunction, self).__init__()
def _filter(self, image):
_, nChannels, height, width = image.size()
# GPUが利用可能ならGPUを利用する。
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
kernel = torch.FloatTensor([[ 0, 1, 0],
[ 0, -2, 0],
[ 0, 1, 0]]).to(device) # Tensorをdeviceに転送する。
------------------------------------------
(omitted)
------------------------------------------
def train():
------------------------------------------
(omitted)
------------------------------------------
# GPUが利用可能ならGPUを利用する。
if torch.cuda.is_available():
device = "cuda"
torch.backends.cudnn.benchmark=True
else:
device = "cpu"
# 分散処理システムを利用する。
os.environ['MASTER_ADDR'] = 'localhost' # 処理を実行するマスター マシンのIPアドレスを指定する。
os.environ['MASTER_PORT'] = '12355' # 利用する空きポート番号を指定する。
torch.distributed.init_process_group(backend="nccl", rank=0, world_size=1)
# 通信バックエンドの1つであるNCCLバックエンドは、CUDAのtensorを対象にした集合演算に最適化された実装となっている。
# rank: distributed process number, world_size: number of distributed processes
# モデルのインスタンスを作成する。
model =Model()
#model = torch.compile(model)
if os.path.isfile(checkpointPath + "model.pth"):
model.load_state_dict(torch.load(checkpointPath + "model.pth", map_location=torch.device(device)))
# モデルのデータをdeviceに置く。
model.to(device)
# モデルを細切れにして順伝播でCPU Offloadingするように設定する。
model = FullyShardedDataParallel(model, cpu_offload=CPUOffload(offload_params=True))
# オプティマイザーを作成する。
optimizer = torch.optim.RAdam(params=model.parameters(), lr=learningRate, betas=(0.9, 0.999), eps=1e-08, weight_decay=weightDecay)
# 損失関数のインスタンスを作成する。
lossFunction = LossFunction() # torch.nn.Moduleを継承している。
------------------------------------------
(omitted)
------------------------------------------PyTorch 2.0に標準で入っている機能である “FullyShardedDataParallel” (FSDP)と “torch.autograd.graph.save_on_cpu()” を利用しました。
まず、
model = FullyShardedDataParallel(model, cpu_offload=CPUOffload(offload_params=True))でモデルを細切れにして順伝播でCPU Offloadingするように設定します。
このFullyShardedDataParallel機能は分散処理システムの一部ですので、
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'torch.distributed.init_process_group(backend="nccl", rank=0, world_size=1)として分散処理グループを初期化する必要が有りました。
ローカル マシンでCPU + GPU1基で処理するなら、 “MASTER_ADDR” は “localhost”, “MASTER_PORT” は “12355” など、”rank=0” , “world_size=1“で大丈夫です。
次に、順伝播(forward)部分で
with torch.autograd.graph.save_on_cpu(pin_memory=True):として計算の途中経過のデータをCPUのメインメモリーの確保した領域に保存するように設定します。
戻り値(return)までを “with” ブロックに含めないといけません。
以下の様にTensorを作成したらGPUに転送します。(Tensorを転送)
# GPUが利用可能ならGPUを利用する。
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
kernel = torch.FloatTensor([[ 0, 1, 0],
[ 0, -2, 0],
[ 0, 1, 0]]).to(device) # Tensorをdeviceに転送する。これで漸くCPU OffloadingでGPUのVRAM + CPUのメインメモリーで大きなサイズのモデルで機械学習のトレーニングを実行出来ました。
[CPU実行]
Epoch: 0 Step: 12 Time: 33.39 Loss: 0.06070666
Epoch: 0 Step: 13 Time: 33.27 Loss: 0.06636295
Epoch: 0 Step: 14 Time: 33.33 Loss: 0.06011158
Epoch: 0 Step: 15 Time: 33.30 Loss: 0.05509898
Epoch: 0 Step: 16 Time: 33.24 Loss: 0.05788897
Epoch: 0 Step: 17 Time: 33.22 Loss: 0.07998817
Epoch: 0 Step: 18 Time: 33.13 Loss: 0.05913256
Epoch: 0 Step: 19 Time: 33.20 Loss: 0.07819811
Epoch: 0 Step: 20 Time: 33.24 Loss: 0.05797869[GPU+CPU Offloading実行]
Epoch: 0 Step: 12 Time: 4.79 Loss: 0.06264534
Epoch: 0 Step: 13 Time: 4.76 Loss: 0.07903091
Epoch: 0 Step: 14 Time: 4.80 Loss: 0.10520715
Epoch: 0 Step: 15 Time: 4.74 Loss: 0.06296450
Epoch: 0 Step: 16 Time: 4.81 Loss: 0.05967178
Epoch: 0 Step: 17 Time: 4.77 Loss: 0.07344814
Epoch: 0 Step: 18 Time: 4.77 Loss: 0.05387807
Epoch: 0 Step: 19 Time: 4.78 Loss: 0.07786547
Epoch: 0 Step: 20 Time: 4.76 Loss: 0.07156084CPU実行では平均33.26s/Step、GPU+CPU Offloading実行では平均4.78s/Stepですので、約7倍高速化した事になりますね。
CPU OffloadingではGPU <–> CPU間でのデータの移動に余計な時間が掛かりますが、それでもGPU処理は高速です。
$ nvidia-smi
Fri Mar 10 23:35:34 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3060 On | 00000000:01:00.0 Off | N/A |
| 36% 61C P2 101W / 100W| 9098MiB / 12288MiB | 100% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1850 G /usr/lib/xorg/Xorg 106MiB |
| 0 N/A N/A 1991 G /usr/bin/gnome-shell 45MiB |
| 0 N/A N/A 4342 G /home/-----/firefox/firefox 126MiB |
| 0 N/A N/A 14452 C python3 8776MiB |
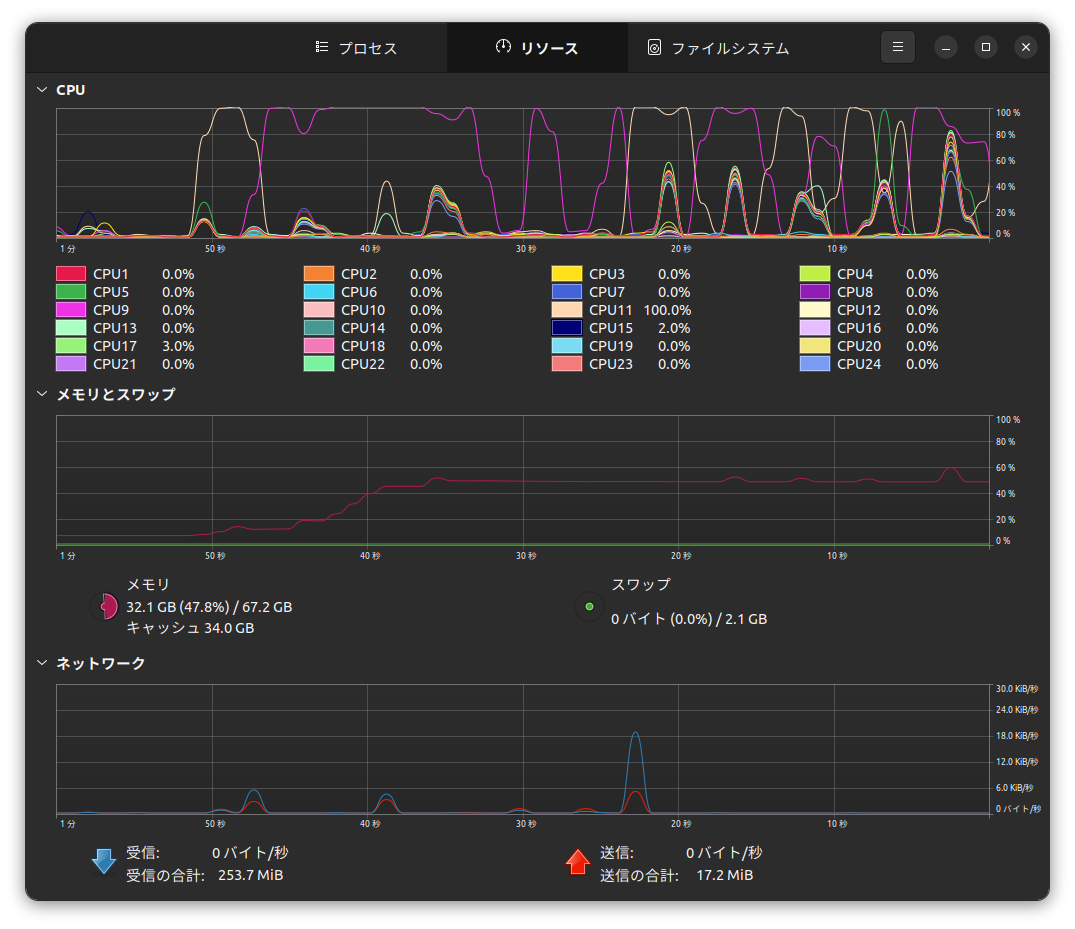
+---------------------------------------------------------------------------------------+グラフィクス カードでは機械学習プロセスが8,776MiBのVRAMを消費していますね。
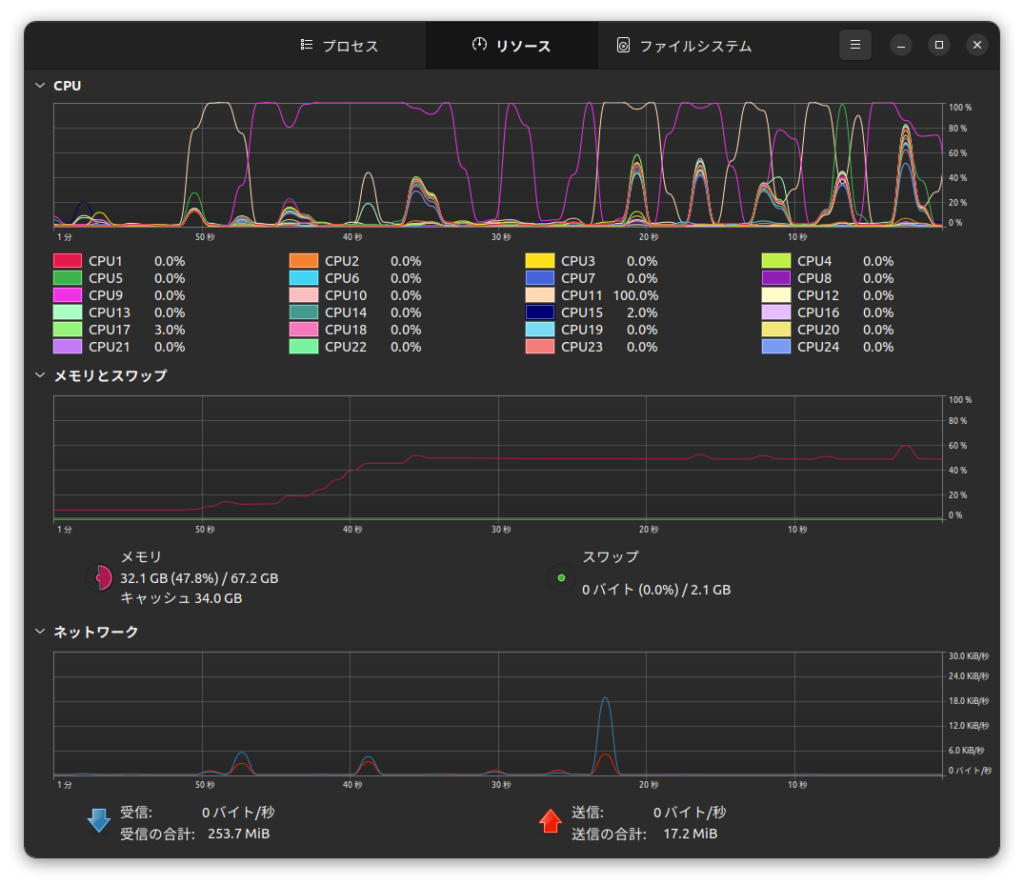
同時にCPU側は計算負荷は低く、メインメモリーは全プロセス合計で32.1GBの消費量となっており、しっかりとCPU Offloadingされているのが分かります。


コメント